
The disk is the slowest part of the server.
Proper storage configuration is critical to the optimal performance and operation of SQL Server.
Below are some of the most common best practices for storage that Microsoft recommends to improve SQL Server performance, reliability, and security.
By the way, this check is a part of our SQL Server Health Check service.
Disk Hardware
Over the past five decades, Hard Disk Drives (HDD) have made regular improvements in reliability, capacity, and speed.
Solid-State Drives (SSD) are faster and use less energy than HDDs.
They have been available at capacities and prices suitable for server use in the last decade.
To improve the reliability of SSDs, use enterprise-class drives, which provide significantly better IO performance and significantly less prone to errors.
File system
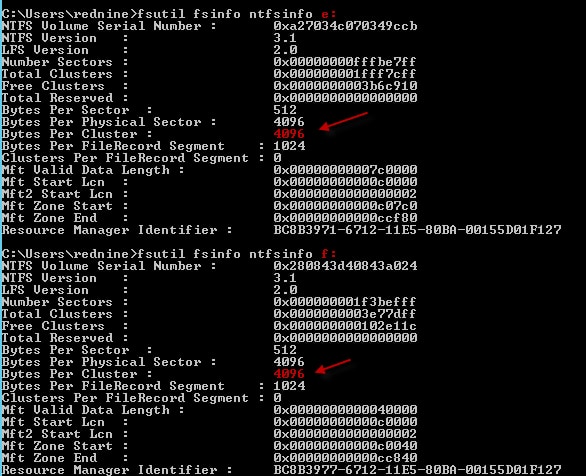
SQL Server does the majority of I/O operations in 8K or 64KB chunks and performs the best when storage, where DB files live, is formatted using 64KB (system cluster size).
You can check the disk cluster size using the code below on command prompt as administrator. Just change the Letter “E” to your Drive.
fsutil fsinfo ntfsinfo E:
It is not easy to fix after the fact, but if you can get the maintenance window, then it’s worth making the change.
A simple way to do this is to add a new drive, format drive correctly, move SQL files to it, delete old Drive. Proceed to another drive, etc.
If you are using a SAN, you should also look into the alignments against the LUN divisions. In the case of a virtual machine, consider this filesystem layer too.
Data Storage
Separate the Data(MDF), Log (LDFs), and tempDB files into different physical drives.
Make sure that you have it all separate from the operating system drive “C:”, even if it is into another partition on the same hardware.
Also, never share the same disk with backups and live databases. If the disk fails, you lose both – Databases and the backups.
Data files and temp dbs usually have more random access than log files, but that depends on the workload. So, when possible, use RAID 1+0 to improve write performance.
Filegroups and data files
For starters, you want to have multiple FGs, which contain multiple files.
Ideally those files all are on separate drives. Which makes reading/writing data and index faster. Since read/write operation can now be multithreaded and, multiple physical disks can “help.”
If some data is stale and doesn’t change much (say data that is old), that data can be put into a separate FG, then backed up only once and then set to read_only.
And now you only have to back up only the latest data. Which reduces the time it takes to backup, backup sizes, restore times, etc.
This strategy also allows us to place older data on slower/cheaper storage.
In case of disaster, you want to have the least amount of data possible inside PRIMARY filegroup because you can’t get DB online until it is recovered.
Therefore, it’s a good idea to keep the PRIMARY as small as possible.
That way, during the disaster, you could bring PRIMARY online, then-current year’s data, and at that point, your DB is live. While in the background, we may be restoring older data without affecting DB availability or users even knowing about this.
This also makes restore to lower environments, such as DEV, QA, UAT, smaller & faster, as now you don’t have to restore the full data.
Other considerations
- Review the database’s auto-growth settings and the internal fragmentation on the transaction log (VLFs).
- Consider to enable Instant File Initialization and trace flags to control specific behaviors in SQL Server.
More information
Microsoft- Place Data and Log Files on Separate Drives.
Microsoft – Database Files and Filegroups.
Microsoft – Storage configuration for SQL Server VMs.
Do Not Keep Your SQL Server Databases on a System Drive, Viacheslav Maliutin- MSSQLTips.
VMWare – SQL Server Configuration.
